- The Spouse table, in the COMPANY database, is a weak entity because its primary key is dependent on the Employee table. Without a corresponding employee record, the spouse record would not exist.
An entity is considered strong if it can exist apart from all of its related entities.
- Kernels are strong entities.
- A table without a foreign key or a table that contains a foreign key that can contain nulls is a strong entity
Another term to know is entity type which defines a collection of similar entities.
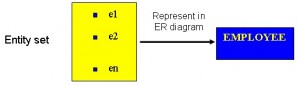
An entity set is a collection of entities of an entity type at a particular point of time. In an entity relationship diagram (ERD), an entity type is represented by a name in a box. For example, in Figure 8.1, the entity type is EMPLOYEE.
Existence dependency
An entity’s existence is dependent on the existence of the related entity. It is existence-dependent if it has a mandatory foreign key (i.e., a foreign key attribute that cannot be null). For example, in the COMPANY database, a Spouse entity is existence -dependent on the Employee entity.
Kinds of Entities
You should also be familiar with different kinds of entities including independent entities, dependent entities and characteristic entities. These are described below.
Independent entities
Independent entities, also referred to as kernels, are the backbone of the database. They are what other tables are based on. Kernels have the following characteristics:
- They are the building blocks of a database.
- The primary key may be simple or composite.
- The primary key is not a foreign key.
- They do not depend on another entity for their existence.
If we refer back to our COMPANY database, examples of an independent entity include the Customer table, Employee table or Product table.
Dependent entities
Dependent entities, also referred to as derived entities, depend on other tables for their meaning. These entities have the following characteristics:
- Dependent entities are used to connect two kernels together.
- They are said to be existence dependent on two or more tables.
- Many to many relationships become associative tables with at least two foreign keys.
- They may contain other attributes.
- The foreign key identifies each associated table.
- There are three options for the primary key:
- Use a composite of foreign keys of associated tables if unique
- Use a composite of foreign keys and a qualifying column
- Create a new simple primary key
Characteristic entities
Characteristic entities provide more information about another table. These entities have the following characteristics:
- They represent multivalued attributes.
- They describe other entities.
- They typically have a one to many relationship.
- The foreign key is used to further identify the characterized table.
- Options for primary key are as follows:
- Use a composite of foreign key plus a qualifying column
- Create a new simple primary key. In the COMPANY database, these might include:
- Employee ( EID, Name, Address, Age, Salary) – EID is the simple primary key.
- EmployeePhone ( EID, Phone ) – EID is part of a composite primary key. Here, EID is also a foreign key.
Attributes
Each entity is described by a set of attributes (e.g., Employee = (Name, Address, Birthdate (Age) , Salary).
Each attribute has a name, and is associated with an entity and a domain of legal values. However, the information about attribute domain is not presented on the ERD.
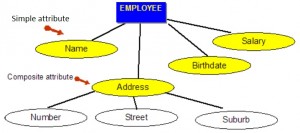
In the entity relationship diagram, shown in Figure 8.2, each attribute is represented by an oval with a name inside.

Types of Attributes
There are a few types of attributes you need to be familiar with. Some of these are to be left as is, but some need to be adjusted to facilitate representation in the relational model. This first section will discuss the types of attributes. Later on we will discuss fixing the attributes to fit correctly into the relational model.
Simple attributes
Simple attributes are those drawn from the atomic value domains; they are also called single-valued attributes. In the COMPANY database, an example of this would be: Name = ; Age =
Composite attributes
Composite attributes are those that consist of a hierarchy of attributes. Using our database example, and shown in Figure 8.3, Address may consist of Number, Street and Suburb. So this would be written as → Address =
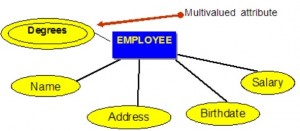
Multivalued attributes
Multivalued attributes are attributes that have a set of values for each entity. An example of a multivalued attribute from the COMPANY database, as seen in Figure 8.4, are the degrees of an employee: BSc, MIT, PhD.
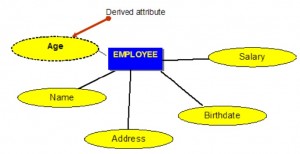
Derived attributes
Derived attributes are attributes that contain values calculated from other attributes. An example of this can be seen in Figure 8.5. Age can be derived from the attribute Birthdate. In this situation, Birthdate is called a stored attribute, which is physically saved to the database.
Keys
An important constraint on an entity is the key. The key is an attribute or a group of attributes whose values can be used to uniquely identify an individual entity in an entity set.
Types of Keys
There are several types of keys. These are described below.
Candidate key
A candidate key is a simple or composite key that is unique and minimal. It is unique because no two rows in a table may have the same value at any time. It is minimal because every column is necessary in order to attain uniqueness.
From our COMPANY database example, if the entity is Employee(EID, First Name, Last Name, SIN, Address, Phone, BirthDate, Salary, DepartmentID), possible candidate keys are:
- EID, SIN
- First Name and Last Name – assuming there is no one else in the company with the same name
- Last Name and DepartmentID – assuming two people with the same last name don’t work in the same department
Composite key
A composite key is composed of two or more attributes, but it must be minimal.
Using the example from the candidate key section, possible composite keys are:
- First Name and Last Name – assuming there is no one else in the company with the same name
- Last Name and Department ID – assuming two people with the same last name don’t work in the same department
Primary key
The primary key is a candidate key that is selected by the database designer to be used as an identifying mechanism for the whole entity set. It must uniquely identify tuples in a table and not be null. The primary key is indicated in the ER model by underlining the attribute.
- A candidate key is selected by the design er to uniquely identify tuples in a table. It must not be null.
- A key is chosen by the database designer to be used as an identifying mechanism for the whole entity set. This is referred to as the primary key. This key is indicated by underlining the attribute in the ER model.
In the following example, EID is the primary key:
Employee( EID , First Name, Last Name, SIN, Address, Phone, BirthDate, Salary, DepartmentID)
Secondary key
A secondary key is an attribute used strictly for retrieval purposes (can be composite), for example: Phone and Last Name.
Alternate key
Alternate keys are all candidate keys not chosen as the primary key.
Foreign key
A foreign key (FK) is an attribute in a table that references the primary key in another table OR it can be null. Both foreign and primary keys must be of the same data type.
In the COMPANY database example below, DepartmentID is the foreign key:
Employee(EID, First Name, Last Name, SIN, Address, Phone, BirthDate, Salary, DepartmentID)
Nulls
A null is a special symbol, independent of data type, which means either unknown or inapplicable. It does not mean zero or blank. Features of null include:
- No data entry
- Not permitted in the primary key
- Should be avoided in other attributes
- Can represent
- An unknown attribute value
- A known, but missing, attribute value
- A “not applicable” condition
NOTE: The result of a comparison operation is null when either argument is null. The result of an arithmetic operation is null when either argument is null (except functions that ignore nulls).
Example of how null can be used
Use the Salary table (Salary_tbl) in Figure 8.6 to follow an example of how null can be used.
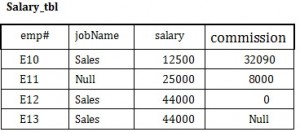
To begin, find all employees (emp#) in Sales (under the jobName column) whose salary plus commission are greater than 30,000.
- SELECT emp# FROM Salary_tbl
- WHERE jobName = Sales AND
- (commission + salary) > 30,000 –> E10 and E12
This result does not include E13 because of the null value in the commission column. To ensure that the row with the null value is included, we need to look at the individual fields. By adding commission and salary for employee E13, the result will be a null value. The solution is shown below.
- SELECT emp# FROM Salary_tbl
- WHERE jobName = Sales AND
- (commission > 30000 OR
- salary > 30000 OR
- (commission + salary) > 30,000 –>E10 and E12 and E13
Relationships
Relationships are the glue that holds the tables together. They are used to connect related information between tables.
Relationship strength is based on how the primary key of a related entity is defined. A weak, or non-identifying, relationship exists if the primary key of the related entity does not contain a primary key component of the parent entity. Company database examples include:
- Customer( CustID , CustName)
- Order( OrderID , CustID, Date)
A strong, or identifying, relationship exists when the primary key of the related entity contains the primary key component of the parent entity. Examples include:
- Course( CrsCode , DeptCode, Description)
- Class( CrsCode, Section , ClassTime…)
Types of Relationships
Below are descriptions of the various types of relationships.
One to many (1:M) relationship
A one to many (1:M) relationship should be the norm in any relational database design and is found in all relational database environments. For example, one department has many employees. Figure 8.7 shows the relationship of one of these employees to the department.
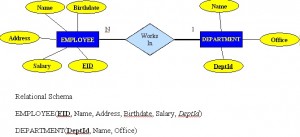
One to one (1:1) relationship
A one to one (1:1) relationship is the relationship of one entity to only one other entity, and vice versa. It should be rare in any relational database design. In fact, it could indicate that two entities actually belong in the same table.
An example from the COMPANY database is one employee is associated with one spouse, and one spouse is associated with one employee.
Many to many (M:N) relationships
For a many to many relationship, consider the following points:
- It cannot be implemented as such in the relational model.
- It can be changed into two 1:M relationships.
- It can be implemented by breaking up to produce a set of 1:M relationships.
- It involves the implementation of a composite entity.
- Creates two or more 1:M relationships.
- The composite entity table must contain at least the primary keys of the original tables.
- The linking table contains multiple occurrences of the foreign key values.
- Additional attributes may be assigned as needed.
- It can avoid problems inherent in an M:N relationship by creating a composite entity or bridge entity. For example, an employee can work on many projects OR a project can have many employees working on it, depending on the business rules. Or, a student can have many classes and a class can hold many students.
Figure 8.8 shows another another aspect of the M:N relationship where an employee has different start dates for different projects . Therefore, we need a JOIN table that contains the EID, Code and StartDate.
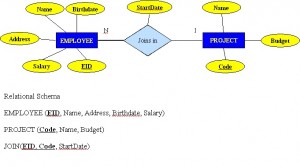
Example of mapping an M:N binary relationship type
- For each M:N binary relationship, identify two relations.
- A and B represent two entity types participating in R.
- Create a new relation S to represent R.
- S needs to contain the PKs of A and B. These together can be the PK in the S table OR these together with another simple attribute in the new table R can be the PK.
- The combination of the primary keys (A and B) will make the primary key of S.
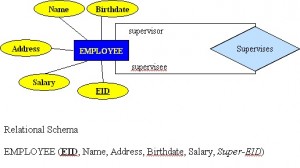
Unary relationship (recursive)
A unary relationship, also called recursive, is one in which a relationship exists between occurrences of the same entity set. In this relationship, the primary and foreign keys are the same, but they represent two entities with different roles. See Figure 8.9 for an example.
For some entities in a unary relationship , a separate column can be created that refers to the primary key of the same entity set.
Ternary Relationships
A ternary relationship is a relationship type that involves many to many relationships between three tables.
Refer to Figure 8.10 for an example of mapping a ternary relationship type. Note n-ary means multiple tables in a relationship. (Remember, N = many.)
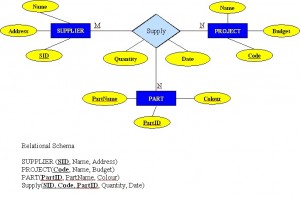
- For each n-ary (> 2) relationship, create a new relation to represent the relationship.
- The primary key of the new relation is a combination of the primary keys of the participating entities that hold the N (many) side.
- In most cases of an n-ary relationship, all the participating entities hold a many side.
alternate key: all candidate keys not chosen as the primary keycandidate key: a simple or composite key that is unique (no two rows in a table may have the same value) and minimal (every column is necessary)
characteristic entities: entities that provide more information about another table
composite attributes: attributes that consist of a hierarchy of attributes
composite key: composed of two or more attributes, but it must be minimal
dependent entities: these entities depend on other tables for their meaning
derived attributes: attributes that contain values calculated from other attributes
derived entities: see dependent entities
EID: employee identification (ID)
entity: a thing or object in the real world with an independent existence that can be differentiated from other objects
entity relationship (ER) data model: also called an ER schema , are represented by ER diagrams. These are well suited to data modelling for use with databases.
entity relationship schema : see entity relationship data model
entity set:a collection of entities of an entity type at a point of time
entity type: a collection of similar entities
foreign key (FK): an attribute in a table that references the primary key in another table OR it can be null
independent entity: as the building blocks of a database, these entities are what other tables are based on
kernel: see independent entity
key: an attribute or group of attributes whose values can be used to uniquely identify an individual entity in an entity set
multivalued attributes: attributes that have a set of values for each entity
n-ary: multiple tables in a relationship
null: a special symbol, independent of data type, which means either unknown or inapplicable; it does not mean zero or blank
recursive relationship: see unary relationship
relationships: the associations or interactions between entities; used to connect related information between tables
relationship strength: based on how the primary key of a related entity is defined
secondary key an attribute used strictly for retrieval purposes
simple attributes: drawn from the atomic value domains
SIN: social insurance number
single-valued attributes: see simple attributes
stored attribute: saved physically to the database
ternary relationship: a relationship type that involves many to many relationships between three tables.
unary relationship: one in which a relationship exists between occurrences of the same entity set.
- What two concepts are ER modelling based on?
- The database in Figure 8.11 is composed of two tables. Use this figure to answer questions 2.1 to 2.5.
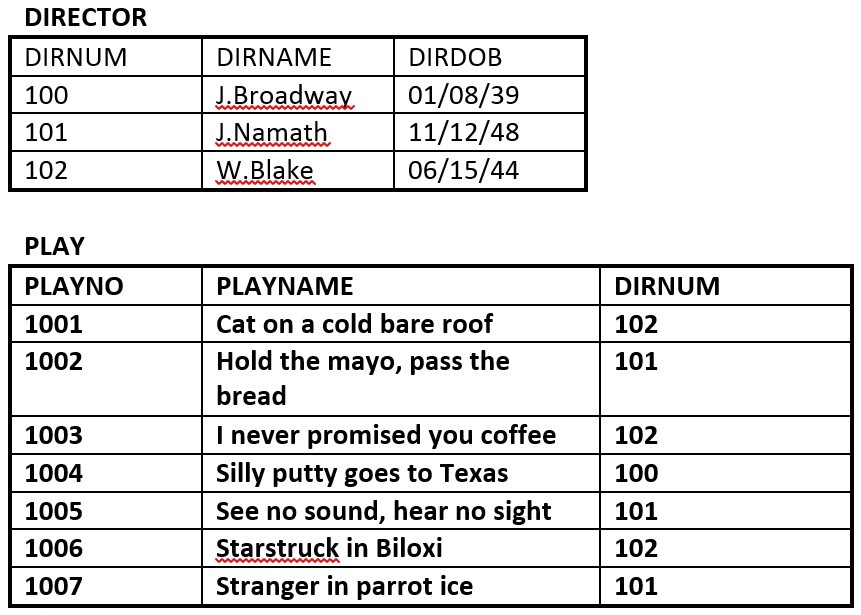
- Identify the primary key for each table.
- Identify the foreign key in the PLAY table.
- Identify the candidate keys in both tables.
- Draw the ER model.
- Does the PLAY table exhibit referential integrity? Why or why not?
- Define the following terms (you may need to use the Internet for some of these):
schema
host language
data sublanguage
data definition language
unary relation
foreign key
virtual relation
connectivity
composite key
linking table - The RRE Trucking Company database includes the three tables in Figure 8.12. Use Figure 8.12 to answer questions 4.1 to 4.5.
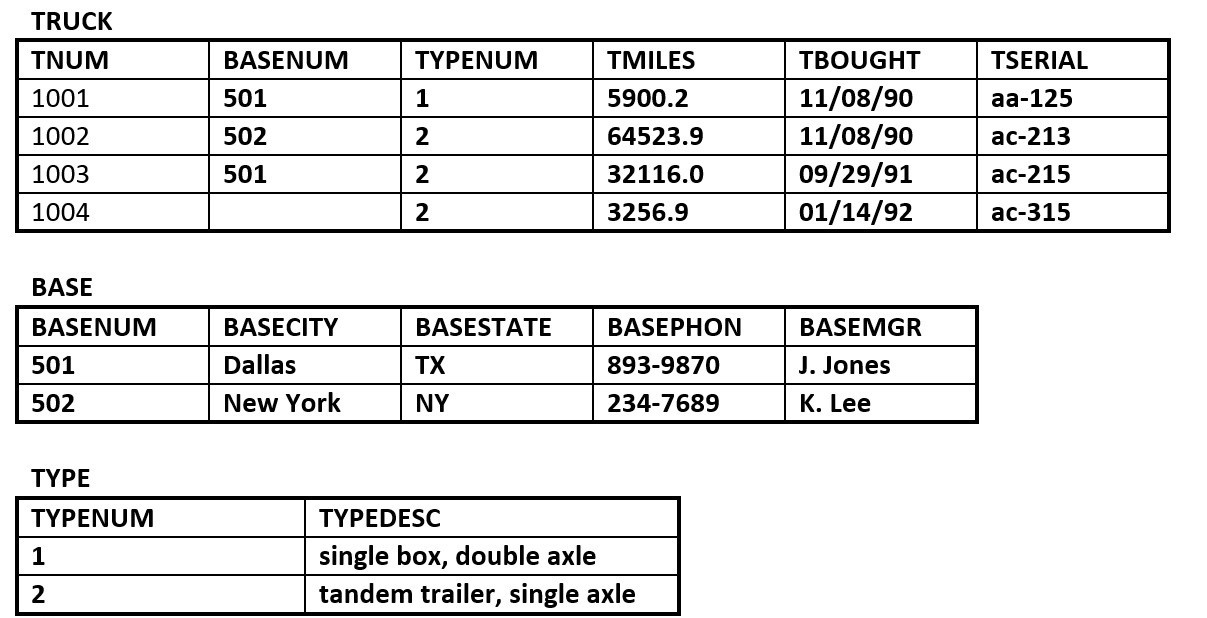
- Identify the primary and foreign key(s) for each table.
- Does the TRUCK table exhibit entity and referential integrity? Why or why not? Explain your answer.
- What kind of relationship exists between the TRUCK and BASE tables?
- How many entities does the TRUCK table contain ?
- Identify the TRUCK table candidate key(s).
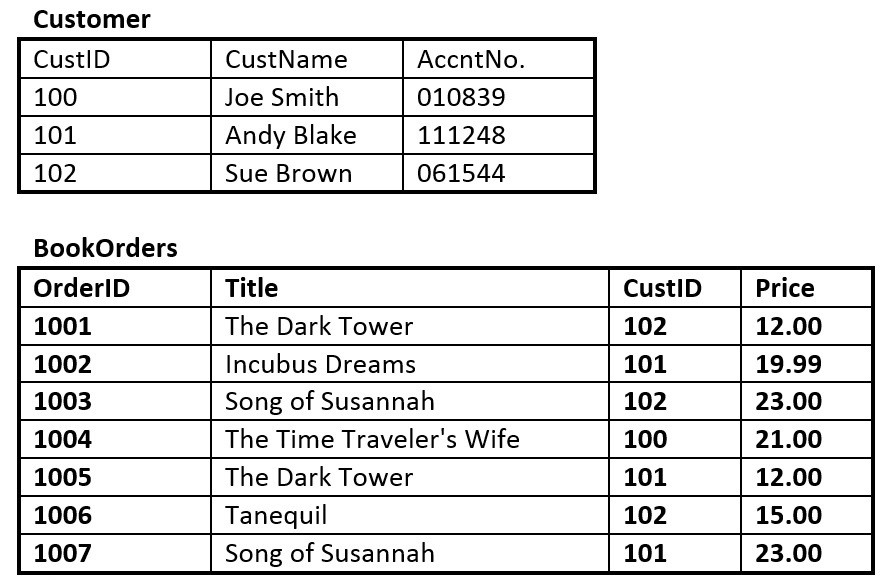
- Suppose you are using the database in Figure 8.13, composed of the two tables. Use Figure 8.13 to answer questions 5.1 to 5.6.
- Identify the primary key in each table.
- Identify the foreign key in the BookOrders table.
- Are there any candidate keys in either table?
- Draw the ER model.
- Does the BookOrders table exhibit referential integrity? Why or why not?
- Do the tables contain redundant data? If so which table(s) and what is the redundant data?
- Looking at the student table in Figure 8.14, list all the possible candidate keys. Why did you select these?
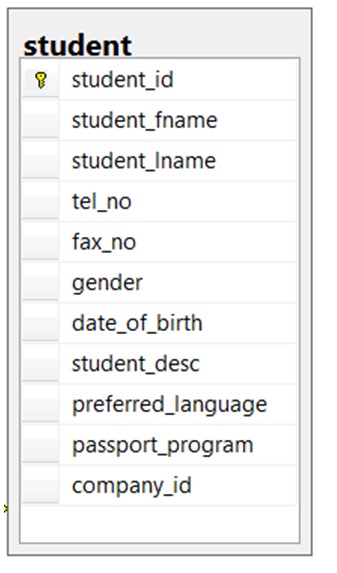
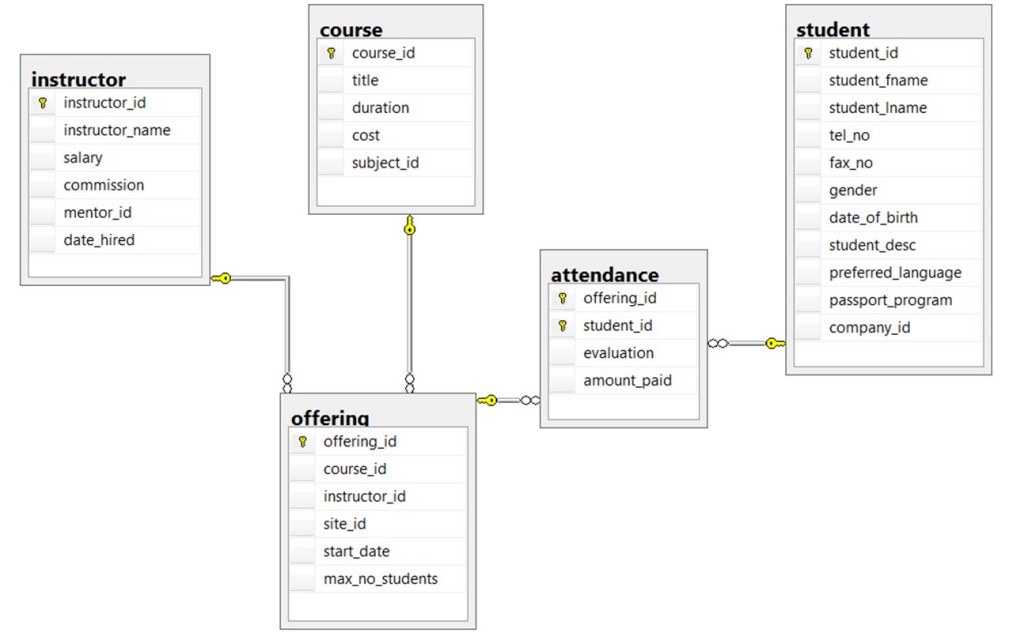 Use the ERD of a school database in Figure 8.15 to answer questions 7 to 10.
Use the ERD of a school database in Figure 8.15 to answer questions 7 to 10. - Identity all the kernels and dependent and characteristic entities in the ERD.
- Which of the tables contribute to weak relationships? Strong relationships?
- Looking at each of the tables in the school database in Figure 8.15, which attribute could have a NULL value? Why?
- Which of the tables were created as a result of many to many relationships?
Also see Appendix B: Sample ERD Exercises
Attribution
This chapter of Database Design (including images, except as otherwisse noted) is a derivative copy of Data Modeling Using Entity-Relationship Model by Nguyen Kim Anh licensed under Creative Commons Attribution License 3.0 license
The following material was written by Adrienne Watt:
- Nulls section and example
- Key Terms
- Exercises
